
Page 69 - My FlipBook
P. 69
“Эрдмийн чуулган-2023” ЭРДЭМ ШИНЖИЛГЭЭНИЙ БҮТЭЭЛИЙН ЭМХЭТГЭЛ
Дараах тэгшитгэлээр өгөгдсөн ерөнхий bellman алдаа (MBSE) -г багасгах замаар сурдаг
үнэлэгчийг ашиглан утгын функцийн тооцооноос [10].
функцийг тооцоолж болно.
 = lim(Ɣλ) +1
=0
Энд 0 ≤ λ ≤ 1 параметр нь хазайлт ба
дисперсийн хоорондын зөрүүг хянах ба δt нь
дараах байдлаар өгөгдсөн хугацааны саатлын
алдааг илэрхийлнэ.
= + Ɣ ( +1 ) − ( )
Загварыг өгөгдсөн төлөвийн үйлдлийг
тооцоолох бодлогын функц π_ϴ (a|s)-ийг
ойролцоолоход ашигладаг бол шүүмжлэгч
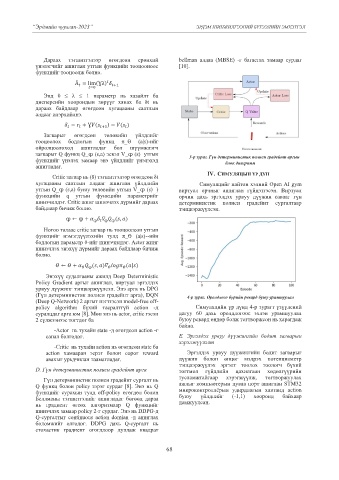
загварыг Q функц Q_ȹ (s,a) эсвэл V_ȹ (s) утгын 3-р зураг. Гүн детерминистик полиси градейнт аргын
функцийг үнэлэх замаар энэ үйлдлийг үнэлэхэд блок диаграмм
ашигладаг.
Critic загвар нь (8) тэгшитгэлээр өгөгдсөн δt IV. СИМУЛЯЦЫН ҮР ДҮН
хугацааны саатлын алдааг ашиглан үйлдлийн Симуляцийг пайтон хэлний Open AI gym
утгын Q_ȹ (s,a) буюу төлөвийн утгын V_ȹ (s) ) виртуал орчныг ашиглан гүйцэтгэсэн. Виртуал
функцийн q утгын функцийн параметрийг орчин дахь эргэлдэх урвуу дүүжин савааг гүн
шинэчилдэг. Critic жинг шинэчлэх дүрмийг дараах детерминистик полиси градейнт сургалтаар
байдлаар бичиж болно. тэнцвэржүүлсэн.
ȹ ← ȹ + ( , )
ȹ ȹ ȹ
Нөгөө талаас critic загвар нь тооцоолсон утгын
функцийг нэмэгдүүлэхийн тулд π_ϴ (a|s)--ийн
бодлогын параметр θ-ийг шинэчилдэг. Actor жинг
шинэчлэх энэхүү дүрмийг дараах байдлаар бичиж
болно.
← + ( , ) ( | )
ȹ
Энэхүү судалгааны ажилд Deep Deterministic
Policy Gradient аргыг ашиглан, виртуал эргэлдэх
урвуу дүүжинг тэнцвэржүүлсэн. Энэ арга нь DPG
(Гүн детерминистик полиси градейнт арга), DQN 4-р зураг. Оролдлого бүрийн ревард буюу урамшуулал
(Deep Q-Network) 2 аргыг нэгтгэсэн model-free off-
policy algorithm бүхий тасралтгүй action -д Симуляцийн үр дүнд 4-р зурагт үзүүлсний
суралцдаг арга юм [8]. Мөн энэ нь actor, critic гэсэн дагуу 60 дахь оролдлогоос эхлэн урамшуулал
2 сүлжээнээс тогтдог ба буюу ревард өндөр болж тогтворжсон нь харагдаж
байна.
-Actor нь тухайн state -д өгөгдсөн action -г
санал болгодог. E. Эргэлдэх урвуу дүүжингийн бодит загварын
хэрэгжүүлэлт
-Critic нь тухайн action нь өгөгдсөн state ба
action хамааран эерэг болон сөрөг reward Эргэлдэх урвуу дүүжингийн бодит загварыг
авахыг урьдчилан таамагладаг. дүүжин болон өнцөг мэдрэх потенциаметр
тэнцвэржүүлэх эргэлт тоолох тоологч бүхий
D. Гүн детерминистик полиси градейнт арга тогтмол гүйдлийн цахилгаан хөдөлгүүрийн
Гүн детерминистик полиси градейнт сургалт нь тусламжтайгаар хэрэгжүүлж, тогтворжуулах
Q функц болон policy зэрэг сурдаг [8]. Энэ нь Q ажлыг компьютерын цуваа порт ашиглан STM32
функцийг сурахын тулд off-policy өгөгдөл болон микроконтроллёрын удирдлагын хавтанд action
Беллманы тэгшитгэлийг ашигладаг бөгөөд дараа буюу үйлдлийг (-1,1) хооронд байхаар
нь градиент өгсөх алгоритмаар Q функцийг дамжуулсан.
шинэчлэх замаар policy 2-г сурдаг. Энэ нь DDPG-д
Q-сургалтыг continuous action domian -д ашиглах
боломжийг олгодог. DDPG дахь Q-сургалт нь
стохастик градиент өгөгдлөөр дундаж квадрат
68